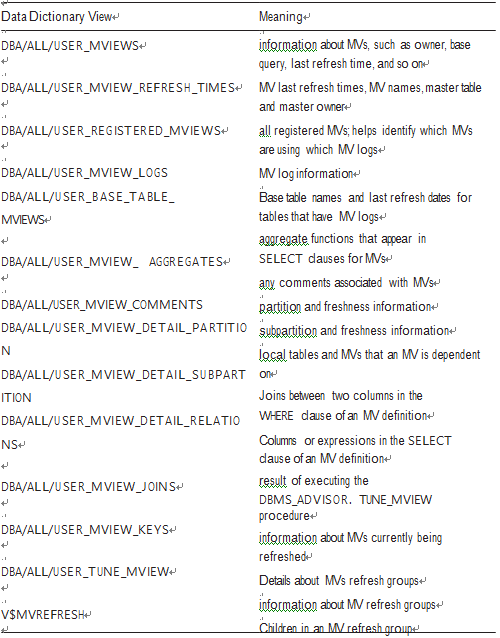
Data Dictionary Architecture- Data Dictionary Fundamentals
If you inherit a database and are asked to maintain and manage it, typically you will inspect the contents of the data dictionary to determine the physical structure of the database and see what events are currently transacting. Besides figuring out what you inherited, these views help to automate processes and troubleshoot problems. Toward this end, Oracle provides two general categories of read-only data dictionary views:
• The contents of your database, such as users, tables, indexes, constraints, privileges, and other objects. These are sometimes referred to as the static CDB/DBA/ALL/USER data dictionary views, and they are based on internal tables stored in the SYSTEM tablespace. The term static, in this sense, means that the information within these views changes only as you make changes to your database, such as adding a user, creating a table, or modifying a column.
• A real-time view of activity in the database, such as users connected to the database, SQL currently executing, memory usage, locks, and I/O statistics. These views are based on virtual memory tables and are referred to as the dynamic performance views. The information in these views is continuously updated by Oracle as events take place within the database. The views are also sometimes called the V$ or GV$ views. GV$ views are global views across all nodes in the database system and normally have an additional column to let you know which node they are referring to.
These types of data dictionary views are described in further detail in the next two sections.
Static Views
Oracle refers to a subset of the data dictionary views as static and based on the physical tables maintained internally by Oracle. The term static can sometimes be a misnomer. For example, the DBA_SEGMENTS and DBA_EXTENTS views change dynamically as the amount of data in your database grows and shrinks. Regardless, Oracle has made the distinction between static and dynamic, and it is important to understand this architecture nuance when querying the data dictionary. There are four levels of static views:
• USER
• ALL
• DBA
• CDB
The USER views contain information available to the current user. For example, the USER_TABLES view contains information about tables owned by the current user. No special privileges are required to select from the USER-level views.
At the next level are the ALL static views. The ALL views show you all object information the current user has access to. For example, the ALL_TABLES view displays all database tables on which the current user can perform any type of DML operation. No special privileges are required to query from the ALL-level views.
Next are the DBA static views. The DBA views contain metadata describing all objects in the database (regardless of ownership or access privilege). To access the DBA views, a DBA role or SELECT_CATALOG_ROLE must be granted to the current user.
The CDB-level views provide information about all pluggable databases within a container database. The CDB-level views report across all containers (root, seed, and all pluggable databases) in a CDB. For instance, if you wanted to view all users within a CDB database, you would do so from the root container, by querying CDB_USERS.
You will notice that many of the static data dictionary and dynamic performance views have a new column, CON_ID. This column uniquely identifies each pluggable database within a container database. The root container has a CON_ID of 1. The seed has a CON_ID of 2. Each new pluggable database created within the CDB is assigned a unique sequential
container ID.
The static views are based on internal Oracle tables, such as USER$, TAB$, and IND$. If you have access to the SYS schema, you can view underlying tables directly via SQL. For most situations, you need to access only the static views that are based on the underlying internal tables.
The data dictionary tables (such as USER$, TAB$, and IND$) are created during the execution of the CREATE DATABASE command. As part of creating a database, the sql. bsq file is executed, which builds these internal data dictionary tables.
The sql.bsq file is generally located in the ORACLE_HOME/rdbms/admin directory; you can view it via an OS editing utility (such as vi, in Linux/Unix, or Notepad in Windows).
The static views are created when you run the catalog.sql script (usually, you run this script once the CREATE DATABASE operation succeeds). The catalog.sql script is located in the ORACLE_HOME/rdbms/admin directory. Figure 10-1 shows the process of creating the static data dictionary views.
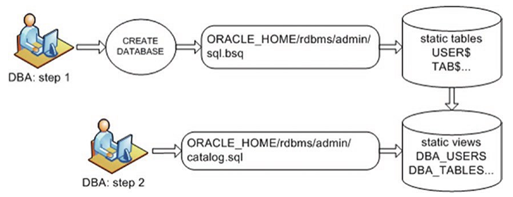
Figure 10–1. Creating the static data dictionary views